Publicación semestral • ISSN 2683-2968 • Marzo 2023 • Número de revista 7
DOI de la revista: https://doi.org/10.22201/dgtic.26832968e
DOI del número: https://doi.org/10.22201/dgtic.26832968e.2023.7
Publicación semestral • ISSN 2683-2968 • Marzo 2023 • Número de revista 7
DOI de la revista: https://doi.org/10.22201/dgtic.26832968e
DOI del número: https://doi.org/10.22201/dgtic.26832968e.2023.7
DOI del artículo: https://doi.org/10.22201/dgtic.26832968e.2022.7.1
3/6
Algunos servicios de redes sociales proveen la ubicación geográfica de los usuarios y/o de las publicaciones. Existen investigaciones en donde los usuarios que permiten se conozca su ubicación son una minoría. Por ejemplo, en [12] se encontró un experimento con 19.6 millones de tuits, solamente el 0.7% tienen habilitada la opción de ubicación geográfica. Dada esta situación, se han desarrollado diversos métodos para inferir de manera automática la ubicación. Estos se pueden clasificar en tres tipos, de acuerdo a la información utilizada para realizar la inferencia. El primer tipo de métodos se basa en la información de los contactos, amigos o seguidores, según sea el caso, del usuario que hace la publicación [13]. El segundo tipo de métodos, se basa en la información de las publicaciones relacionadas, es decir, comentarios, respuestas, etcétera, según sea el tipo de red social [14]. El tercer tipo de métodos, se basa en la información contenida en la publicación misma [15]. Por lo general, se utilizan diversos mecanismos de inferencia basados en aprendizaje computacional, tales como, inferencia Bayesiana, redes neuronales, modelos de regresión, por mencionar algunos.
Los métodos de ubicación geográfica basados en la información contenida en las mismas publicaciones utilizan modelos para el procesamiento de textos sin estructura. Uno de los más empleados es el denominado Extracción de Entidades, también conocido como Reconocimiento de Entidades Nombradas (Named Entity Recognition, NER por sus siglas en inglés). Este modelo consiste en anotar entidades (objetos, personas, lugares, entre otros.) dentro de bloques de texto sin estructura, manejando categorías pre-definidas. Por ejemplo:

En el texto anterior, se clasificó un componente léxico o token, Daniel, como persona; una organización de dos tókenes y una expresión temporal. Los sistemas NER modernos pueden ser tan precisos como personas expertas, por ejemplo, en [16] se describen modelos para el idioma inglés con una precisión de hasta el 92.8%.
Las arquitecturas utilizadas para el proceso de transducción (transformación), que implica la Extracción de Entidades (NER), de un texto sin anotar a un texto anotado1, están basadas en Redes Neuronales (RN). Las RN son un método computacional que consiste en una serie de neuronas artificiales compuestas entre sí. A partir de ciertos datos de entrada, la RN computa datos de salida. En el caso de NER, los datos de entrada consisten de un texto sin anotar, y los datos de salida consisten de un texto anotado. En la figura 1 , se representa gráficamente una RN con una sola capa oculta, también conocida como capa intermedia. Cabe mencionar que las RN, comúnmente se integran por varias capas intermedias.
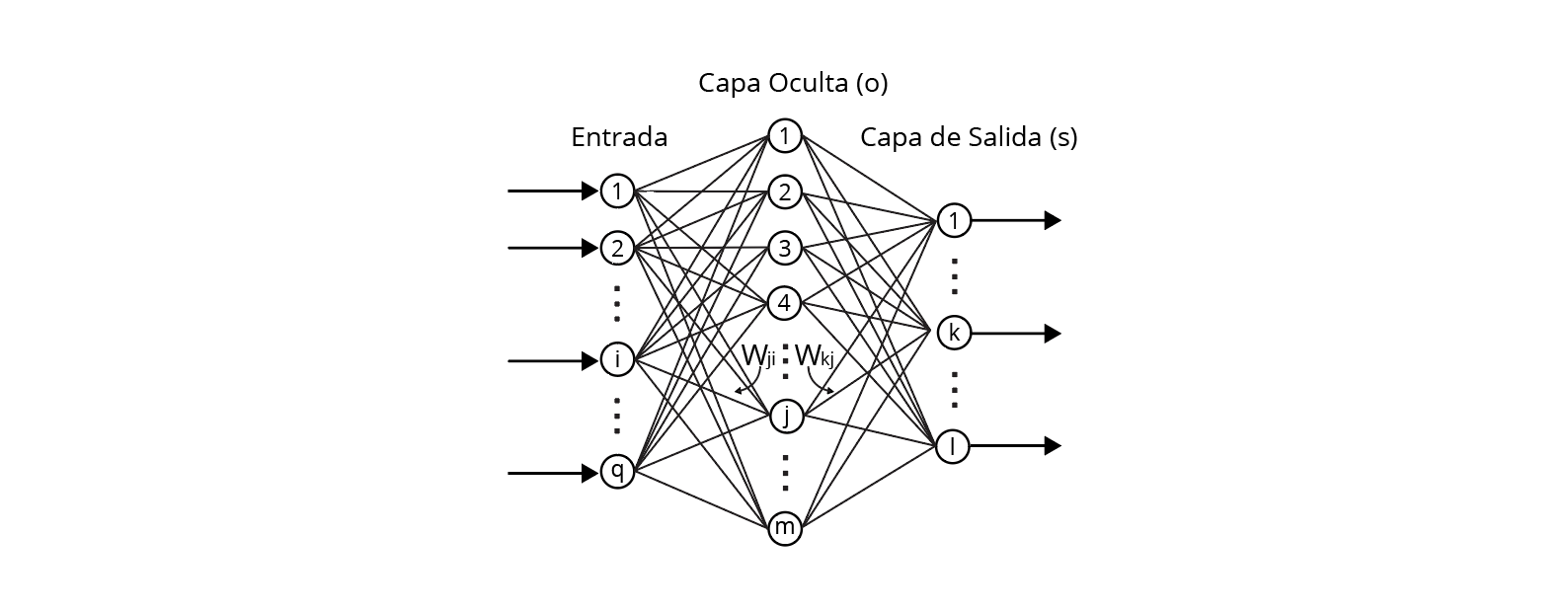
Figura 1. Mroodschild, "Red Neuronal", 2012. [En línea].
Disponible en: https://es.wikipedia.org/wiki/Archivo:CapaOculta.png [Consultado en junio 9, 2022]
El entrenamiento de una RN es un proceso iterativo en el que la composición de las neuronas se ajusta para minimizar el error entre la salida que computa la RN con respecto a un conjunto de datos de entrenamiento. Entre más se entrene un RN, es decir, entre más datos tenga a su disposición, se vuelve más precisa.
La cantidad de capas intermedias de una RN y la cantidad de datos de entrenamiento son los principales factores en el costo de cómputo, tanto de memoria como de tiempo. Una de las técnicas de optimización más útiles en los procesos de cómputo, consiste en su paralelización.
1Anotar entidades (objetos, personas, lugares, etcétera.) dentro de bloques de texto sin estructura utilizando categorías pre-definidas.
Fecha de recepción: 23 de noviembre de 2021
Fecha de publicación: marzo de 2023