Publicación semestral • ISSN 2683-2968 • Marzo 2023 • Número de revista 7
DOI de la revista: https://doi.org/10.22201/dgtic.26832968e
DOI del número: https://doi.org/10.22201/dgtic.26832968e.2023.7
Publicación semestral • ISSN 2683-2968 • Marzo 2023 • Número de revista 7
DOI de la revista: https://doi.org/10.22201/dgtic.26832968e
DOI del número: https://doi.org/10.22201/dgtic.26832968e.2023.7
DOI del artículo: https://doi.org/10.22201/dgtic.26832968e.2022.7.3
Resumen • Introducción • Desarrollo • Resultados • Conclusiones • Bibliografía • [Versión PDF]
2/5
Para la construcción del sistema se buscaron diferentes modelos de arquitectura de redes neuronales convolucionales para identificar cuál de ellas proporciona mejores resultados en imágenes de rayos X de tórax de pulmones. Estas pertenecen a pacientes que presentaban tres clases de diagnóstico: COVID-19, neumonía y pacientes sanos.
El sistema se entrenó con bases de datos provenientes de diversas fuentes y con las clases mencionadas. Esto es importante para que el sistema no solo aprenda de una única fuente y así evitar el sesgo.
Después de probar diversas opciones, al final se emplearon dos modelos distintos que generaron los mejores resultados, se procedió a compararlos y encontrar cuál tiene una mejor precisión. El primero consistió en entrenar dos redes neuronales convolucionales binarias para hacer la clasificación de las tres clases. La primera red neuronal identificó si la imagen estaba enferma o sana. En la clase enfermo se juntaron las imágenes de COVID-19 y neumonía, si el resultado era positivo, se aplica la segunda red neuronal para identificar si la imagen pertenece a COVID-19 o neumonía. El segundo modelo consistió en hacer uso solo de una arquitectura de red neuronal con tres salidas para detectar todas las clases en un solo paso.
El conjunto de imágenes totales se dividió y seleccionó de forma aleatoria para balancear el entrenamiento. En el primer enfoque, la clase enfermo y la clase sano tienen aproximadamente el mismo número de imágenes. Dentro de la clase enfermo, el número de imágenes son las mismas para las clases COVID-19 y neumonía. En el segundo enfoque, las tres clases están balanceadas, es decir, contienen aproximadamente el mismo número de imágenes. Al equilibrar las clases se proporciona un impulso significativo al rendimiento en el entrenamiento de la red neuronal convolucional [6]. El conjunto de validación también está balanceado y corresponde al 20% del conjunto de entrenamiento. Solo en los datos del conjunto de prueba no están balanceadas las clases debido a que no influye en el aprendizaje de los algoritmos. La precisión fue la principal métrica para analizar los resultados obtenidos, para este caso, se utilizó la especificidad y sensibilidad como métricas complementarias.
Las radiografías conformadas por imágenes rayos X de tórax proceden tanto de México como de varios países. Los pacientes tenían un amplio rango de edades, siendo imágenes tanto de hombres como de mujeres, lo que añadió gran diversidad. En ellas se observan pulmones que pertenece a pacientes con COVID-19, neumonía y sanos. La base de datos se integró con dos modalidades de rayos X de tórax, las antero-posteriores (AP) que se toman del pecho hacia la espalda, en ellas se observa la parte delantera del tórax. Las postero-anteriores (PA) que son lo opuesto, se toman de la espalda hacia el pecho, en este caso se ve la parte trasera del tórax. En la figura 1 se muestra un ejemplo de imágenes de rayos X, PA y AP.

Figura 1. Imágenes rayos X de tórax PA y AP. Imagen tomada de en https://radrounds.com/radiology-case-images-teaching-file/chest-x-ray-basics-pa-vs-ap/ [Consultado en septiembre 20, 2021].
Las imágenes de la clase COVID-19 se recopilaron de diversas instituciones médicas y repositorios de datos abiertos, principalmente del Centro Médico Nacional la Raza y del Hospital General de Zona 48 en la ciudad de México, además de la Facultad de Medicina de la Universidad de Montreal se consiguió un notable número de materiales para nutrir el sistema. Los datos sumaron un total de 4,991 imágenes con las modalidades AP y PA [7]-[9].
Las imágenes para la clase neumonía y sano se consiguieron de distintas fuentes, principalmente de algunos institutos de Estados Unidos como la Sociedad Radiológica de América del Norte (RSNA), el Instituto Nacional de Salud (NIH) y la Universidad de California, San Diego, Estados Unidos. Se contó con un total de 15,961 radiografías para la clase neumonía y 70,795 para pulmones sanos, ambas clases con modalidades AP y PA [10]-[11]. El total de los datos para las tres clases fueron 91,747 imágenes.
En las redes neuronales existe una gran variedad de arquitecturas, ya sean versiones establecidas o nuevas, así como la conjunción de nuevas arquitecturas que combinan los aspectos más importantes de cada una en un modelo híbrido. Para nuestro caso se probaron dos modelos, uno en cascada y otro multiclase. Es de conocimiento general que los modelos basados en redes neuronales convolucionales poseen una fase de entrenamiento y otra de validación antes de ser ejecutados con datos de prueba.
En este modelo existen dos redes residuales ResNet 152 en cascada. El proceso se muestra en la figura 2, primero se emplea una ResNet para detectar pulmones sanos y enfermos. En el caso de que la red detecte la información como sano termina el proceso y se clasifica como sano. Si la red neuronal la detecta como enfermo, la información pasará a una segunda ResNet entrenada para clasificar neumonía y COVID-19. En contraste, el modelo analiza una sola red multiclase donde se detecten los tres casos: neumonía, COVID-19 y pacientes sanos.

Figura 2. Diagrama Escalera 2 ResNet 152. Proyecto Análisis de imágenes médicas para la detección y el seguimiento de COVID-19 UNAM, 2022. Fuente: elaboración propia.
Se usaron 8,611 imágenes de tórax para detectar pulmones sanos o enfermos. 4,121 para la clase sano y 4,490 para enfermo. De este conjunto se dedicaron 6,944 imágenes para el entrenamiento y 1,667 imágenes para validación.
Para el entrenamiento se empleó una red neuronal convolucional ResNet 152 y el método de transferencia de aprendizaje (“transfer learning” en inglés), la finalidad es tomar una red donde los pesos y parámetros han sido previamente entrenados con una base de datos de ImageNet, para después sintonizarla (“fine tuning” en inglés) con los datos propios [12].
El proceso del entrenamiento se muestra en la figura 3, en el cual aparece la técnica de congelamiento (“freezing” en inglés), que consiste en mantener los pesos de la red preentrenada, a excepción de la capa de salida y el método de búsqueda de tasa de aprendizaje (“learning rate finder” en inglés), para mejorar la tasa de aprendizaje en el entrenamiento [13]-[14].

Figura 3. Proceso de Entrenamiento Sano y Enfermo. Proyecto Análisis de imágenes médicas para la detección y el seguimiento de COVID-19 UNAM, 2022. Fuente: elaboración propia.
El entrenamiento para detectar enfermedades contó con 4,490 imágenes, de las cuales 2,150 pertenecen a la clase de neumonía y 2,340 son de la clase COVID-19. Un 20% de ellas se editó, se procedió a ejecutar acercamientos, alejamientos, voltear horizontalmente, rotar y agregar más iluminación para tener un aprendizaje más heterogéneo.
Se seleccionaron 3,647 imágenes para el entrenamiento y 843 imágenes para la validación. Se empleó una red neuronal convolucional ResNet 152 preentrenada en ImageNet, y se entrenó con las imágenes de neumonía y COVID-19 para ajustar la red neuronal. En la figura 4 se muestra el proceso gráficamente.
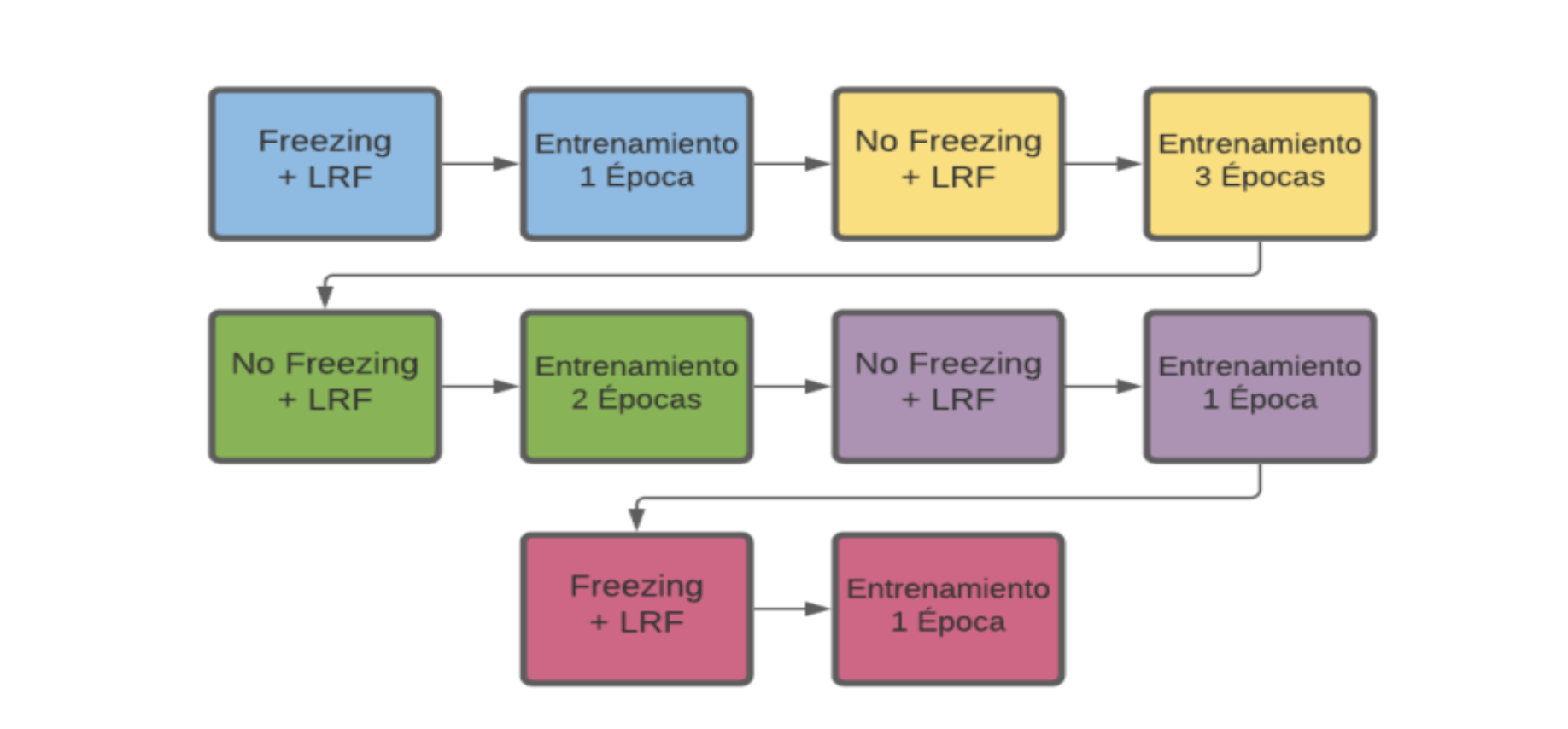
Figura 4. Proceso de Entrenamiento Neumonía y COVID-19. Proyecto Análisis de imágenes médicas para la detección y el seguimiento de COVID-19 UNAM, 2022. Fuente: elaboración propia.
La red convolucional ResNet 152 fue ocupada para la detección de las tres clases, para el entrenamiento se usaron radiografías de tórax, 2,340 con COVID-19, 2,150 con neumonía y 2,021 sanas. Se seleccionaron 5,264 imágenes para el entrenamiento y 1,247 para la validación. La ResNet 152 preentrenada posee “transfer learning” con la base de datos de ImageNet. También se aplicaron las técnicas de freezing y el método learning rate finder, explicados previamente. En la figura 5 se muestra a detalle el proceso realizado.

Figura 5. Proceso de Entrenamiento Sano, Neumonía, COVID-19. Proyecto Análisis de imágenes médicas para la detección y el seguimiento de COVID-19 UNAM, 2022. Fuente: elaboración propia.
Fecha de recepción: 23 de noviembre de 2021
Fecha de publicación: marzo de 2023
Resumen • Introducción • Desarrollo • Resultados • Conclusiones • Bibliografía • [Versión PDF]