Publicación semestral • ISSN 2683-2968 • Octubre 2021 • Número de revista 4
DOI del número: https://doi.org/10.22201/dgtic.26832968e.2021.4
Las anomalías: ¿qué son?, ¿dónde surgen?, ¿cómo detectarlas?
DOI del artículo:https://10.22201/dgtic.26832968e.2021.4.3

1/4
Introducción
Imagine el siguiente escenario. Usted, como todos los días en los últimos años, sale de su casa más o menos a la misma hora, y mientras camina a la estación del metro o a la parada del autobús, observa que algo parece diferente a lo que cotidianamente percibe. Le lleva un momento observar, finalmente, ubica la fuente de lo extraño: el puesto de guajolotas1 se movió unos metros hacia la esquina. Ahora, imagine un segundo escenario. Sale de su casa, y en su caminata a la entrada de la estación del metro, se da cuenta que algo es diferente. Le lleva unos segundos percatarse de lo que se trata: hay un nuevo puesto de tacos en la esquina.
¿Cuál de los dos escenarios es una anomalía? ¿Qué aspectos de la escena visual compara con sus recuerdos, el primer caso es apenas una variación de lo que cotidianamente observa, en tanto que, en el segundo hay algo cualitativamente distinto? Responder a estas preguntas es parte de la problemática a la que se enfrentan los algoritmos de detección de anomalías.
Para llevar al lector a un ámbito más concreto, se le pide observar la figura 1(a), en la que se muestra una distribución de N = 19 puntos, donde dos constituyen anomalías o puntos atípicos. De acuerdo con criterios que describiremos más adelante. Se invita al lector a observar dicha figura con atención antes de seguir con la lectura. ¿Puede usted identificar cuáles serían los puntos candidatos a ser considerados atípicos? ¿Qué lo llevó a hacer su elección de considerar esos puntos como anómalos?
Una de las caracterizaciones más comunes que nos permiten darnos una idea de la diversidad de los datos y, con ello, una aproximación a su nivel de anomalía es la de distancia. Podemos pensarla como una función que permite comparar cosas; mientras más semejantes sean dos objetos, menor es su distancia. De esta forma, entonces, podemos caracterizar la distancia entre cada punto y su vecino más cercano. La figura 1(b) muestra el diámetro que representa a cada círculo en función de la distancia con el vecino más próximo. El vector C es representado por el círculo más grande, puesto que la distancia a su punto más cercano, L, es muy alta. Los puntos R y S son representados por círculos pequeños, porque la distancia entre ellos es baja.
Para seguir en esa línea, podemos obtener la distancia al segundo punto más próximo. De esta forma, contaremos con dos caracterizaciones o atributos para cada vector: la distancia a su primer y segundo vecino.
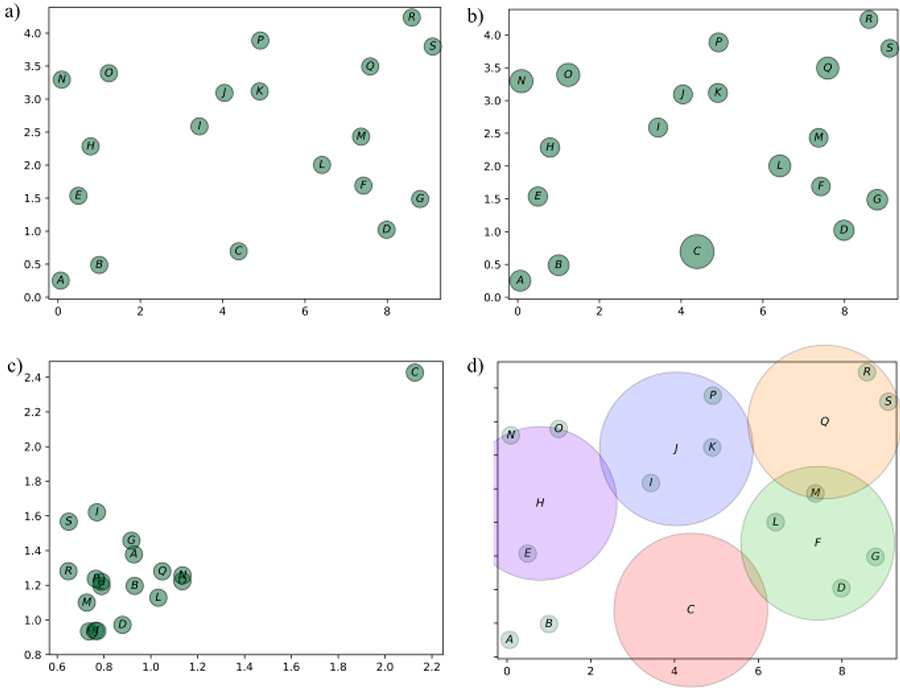
Figura 1. N = 19 puntos. (a): ¿Existe alguna propiedad que sea compartida por la mayoría de los puntos, y que no sea satisfecha por un número reducido de ellos? (b): El radio de cada punto es una función de la distancia al vecino más próximo. El punto C es el más aislado de entre todos los puntos, por lo que el círculo asociado a éste es el de mayor radio. (c) El eje x muestra la distancia al punto más cercano, en tanto que el eje y muestra la distancia al segundo vecino más próximo; por lo que el punto C se muestra claramente distinto a los demás. (d) Se define un vecindario o vecindad mediante un círculo para cada punto, donde aquellos que se encuentren dentro del círculo serán los vecinos. El punto J cuenta con I, K y P como vecinos. Se muestra únicamente el vecindario de los puntos C, F, H, J y O.
Los 19 puntos se grafican en este nuevo espacio de atributos, como lo muestra la figura 1(c). En esta nueva caracterización, se observa que el vector C es muy diferente a los demás, pues se encuentra en una zona muy alejada del resto de los puntos, es decir, aislado. El punto C sería considerado entonces, bajo estos criterios descritos, una anomalía. En la figura 1(d) se muestra a cada punto rodeado por una región circular del mismo radio. Una caracterización de esta región, o vecindario, pasa por contar el número de vectores o puntos dentro de ella. Por lo que, bajo este criterio observamos que 17 de 19 puntos cuentan con dos o tres vecinos, con excepción de los puntos c y f donde el primero carece de vecinos, en tanto que el segundo cuenta con cuatro de ellos.
Las anomalías son eventos que no se asemejan a los eventos usuales [1-3] y surgen en una diversidad de ámbitos. Estas se presentan dentro del área de la medicina, en donde formaciones tumorales son anomalías con respecto a tejido sano; [4] se presentan en biología molecular, cuando ciertos genes se expresan en situaciones en las que no se esperaría que lo hicieran; [5] en las artes, cambios en el estilo de escritura de un autor se identifican con anomalías causadas probablemente por algún trastorno cognitivo. [6,7]
Se le conoce como detección de anomalías al proceso de identificación de observaciones posiblemente anómalas. [8,9] Los algoritmos para detectarlas caen dentro de una rama de la Inteligencia Artificial (IA) conocida como aprendizaje no supervisado. La IA es una disciplina cobijada dentro de las Ciencias de la Computación, pero es resultado de la interacción de investigadores y profesionales de muy diversas disciplinas. [10] Dentro de la IA, un campo de particular interés es el aprendizaje automático, [11] que responde a preguntas tales como: ¿Es posible que un algoritmo aprenda a hacer algo sin que explícitamente se le enseñe la manera de hacerlo? ¿Es posible encontrar un algoritmo que aprenda a distinguir la clase o categoría a la que alguna instancia pertenece?
Los éxitos de la IA en el aprendizaje supervisado han sido notables en muchos ámbitos. Este aprendizaje se da cuando cada punto lleva asociada una etiqueta o clase. Por ejemplo, a una imagen médica, como podría ser el caso de una resonancia magnética cerebral, se le puede asignar la etiqueta de tejido sano o tejido con tumor. Para este caso, un sistema de aprendizaje supervisado intentará encontrar implícitamente una función que asocie a cada píxel de la imagen, o su descripción en realidad, con la clase o etiqueta asociada. De esta forma, el sistema aprenderá a definir en una imagen lo que representa tejido sano y qué lo distingue como tejido tumoral. Este sistema, al ser interrogado sobre una imagen que nunca había analizado, es decir, que no estaba presente en el conjunto de entrenamiento, deberá de decidir cuáles píxeles pertenecen a la clase de tejido sano o de tumor.
1 Entiéndase por una torta de tamal. Véase: https://es.wikipedia.org/wiki/Guajolota
2/5
Desarrollo
Una pregunta pertinente dentro de la IA es la siguiente: ¿Puede un sistema aprender a identificar situaciones inéditas sin que explícitamente un supervisor le diga cuando se encuentra en presencia de una? El proceso de clasificación requiere de una muestra representativa y relevante de las clases de interés. En el caso de detección de las anomalías, la clase correspondiente es extremadamente infrecuente, y por ello, poco numerosa. Por otro lado, la clase de las instancias usuales o habituales suele ser mucho más frecuente que la primera. Esto podría estudiarse bajo la perspectiva de lo que en IA se conoce como clasificación con clases desbalanceadas. [8]. Esto significa que hay dos grupos: uno muy abundante, el de las observaciones típicas, y uno muy reducido, el de las discrepancias, y el desbalanceo, es decir, la diferencia de tamaño en ambos conjuntos es grande.
El esquema de detección de anomalías como un proceso de clasificación es útil en muchas circunstancias, pero es inadecuado para muchos otros casos. Esto se debe a que no es factible conocer con anticipación la clase o etiqueta de los datos, esto es, no se sabe si son o no anomalías. Este último caso es particularmente interesante. En última instancia, puede pensarse que detectarlas es un proceso equivalente a una clasificación de una sola clase, es decir, solamente contamos con las instancias de la clase usual. [9]
Las observaciones del fenómeno, estructura o proceso de interés suelen condensarse en una matriz de datos, en la que cada observación se representa como un renglón y las diferentes caracterizaciones suelen representarse como columnas; por lo que, la mayoría de los análisis computacionales se enfocan a escudriñar dicha estructura matricial. En cierto tipo de análisis, las observaciones se asocian a una clase externa, o etiqueta, lo que permite entrenar algún clasificador. Cabe mencionar que un clasificador es un algoritmo que, mediante la modificación de uno o más parámetros y con base en las caracterizaciones de los objetos, es capaz de decirnos si pertenece a una u otra clase.
Un objeto puede ser descrito de una o más formas, teniendo en cuenta que cada una de esas caracterizaciones es un atributo, rasgo o variable. Ahora bien, cada dato, instancia, punto o vector, indistintamente como los llamaremos, puede pensarse inmerso en un espacio de dimensionalidad igual al número de estas formas, es decir, cada caracterización define una dimensión. En la figura 1, cada punto es descrito por dos atributos: su posición a lo largo del eje horizontal y su ubicación a lo largo del eje vertical.
Las anomalías son detectadas a partir de la matriz de datos, también conocida por otros nombres como matriz de atributos, cubo de datos, conjunto de datos, muestra o base de datos. No obstante, lo relevante de estas es lo que contiene, ya que representa un conjunto de observaciones sobre algún fenómeno, proceso o estructura de interés.
En la gran mayoría de los casos, los datos que buscamos como potenciales discrepancias son multidimensionales. Por ejemplo, la tabla 1 muestra una lista de 40 ciudades en la República Mexicana, donde cada ciudad es descrita por 7 atributos: la precipitación pluvial en los meses de enero, junio y septiembre del 2020; las temperaturas ambiente promedio para los mismos tres meses y el séptimo atributo es la altitud promedio de la ciudad o alcaldía. Cada localidad es, por lo tanto, un punto en el espacio de dimensión 7. Como en la pantalla de la computadora únicamente podemos graficar en una, dos o tres dimensiones, y la mayoría de los humanos podemos percibir de forma natural hasta tres dimensiones, es necesario recurrir a algún algoritmo de reducción de la dimensionalidad para darnos idea de cómo se distribuyen estos 40 puntos en el espacio de dimensión siete.
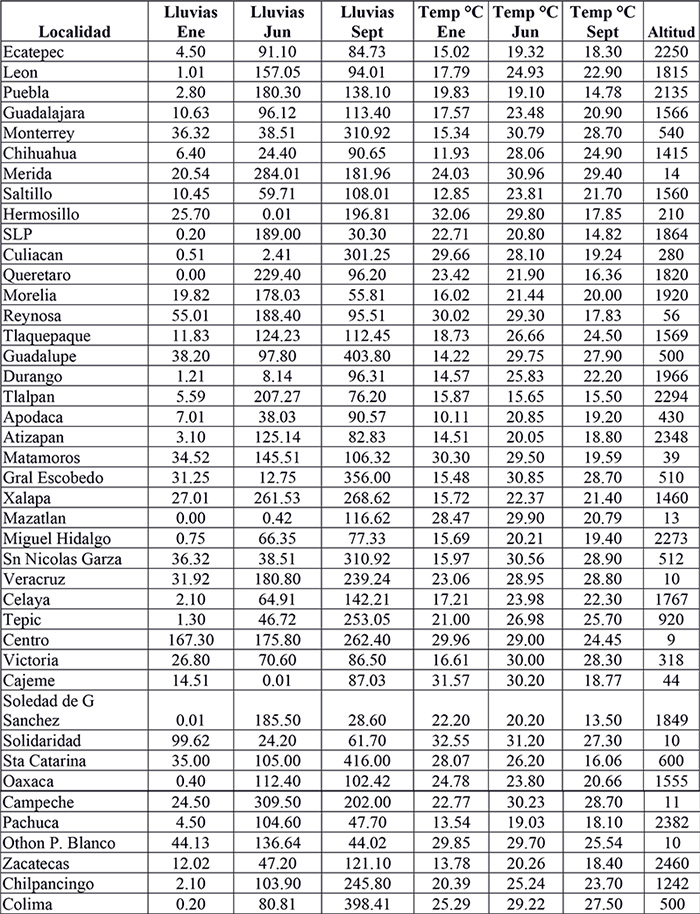
Tabla 1. 42 localidades de la República Mexicana descritas por siete atributos: precipitación pluvial total, temperaturas promedio en enero, junio y septiembre del 2020, todas en grados Celsius, y altitud promedio de la localidad.
La figura 2 muestra una aproximación en dos dimensiones de la distribución de las ciudades en el espacio de atributos. El algoritmo utilizado, fue de escalamiento multidimensional. [12] El tamaño del nombre de la ciudad es indicador de qué tan anómalas es cada una de ellas, de acuerdo con lo que describiremos en breve. Mientras tanto, se invita al lector a observar con detenimiento las figuras 2 (a) y (b). Xalapa y Apodaca se muestran con tamaños de letra mayores en (a), lo que indica que su nivel de anomalía es mayor que el de otras ciudades. En (b), Apodaca disminuye su nivel, pero otras localidades lo aumentan, como es el caso de Tlalpan.
La función que evalúa el grado de anomalidad, o el grado de cotidianeidad de un objeto, se representa en general de manera implícita. Esta función se genera a partir de observaciones que constituyen el conjunto de entrenamiento. Como se mencionó anteriormente, la detección de anomalías puede verse como una clasificación de una sola clase, por ende, las observaciones anómalas son poco frecuentes o inexistentes. De esta forma, en el escenario más estricto, la función que clasifica a un objeto como usual o como discrepancia, se genera únicamente a partir de observaciones habituales. En la práctica, suponemos que el nivel de anomalía de un objeto es un continuo dentro de un rango, usualmente entre 0 y 1. De esta forma, la dicotomía entre objeto usual y observación anómala desaparece, y se sustituye por un número real que proporciona a quien interpreta los datos, una mejor idea del nivel de anomalía de una observación.
De una matriz de datos, como la mostrada en la tabla 1 de nuestro ejemplo, es posible identificar posibles discrepancias bajo una de dos perspectivas. La primera evalúa cada punto con el resto, esto es, suponemos que serán identificadas de manera global. La segunda perspectiva compara a cada punto con los otros en su cercanía, lo que, en otras palabras, significa que serán detectadas de forma local.
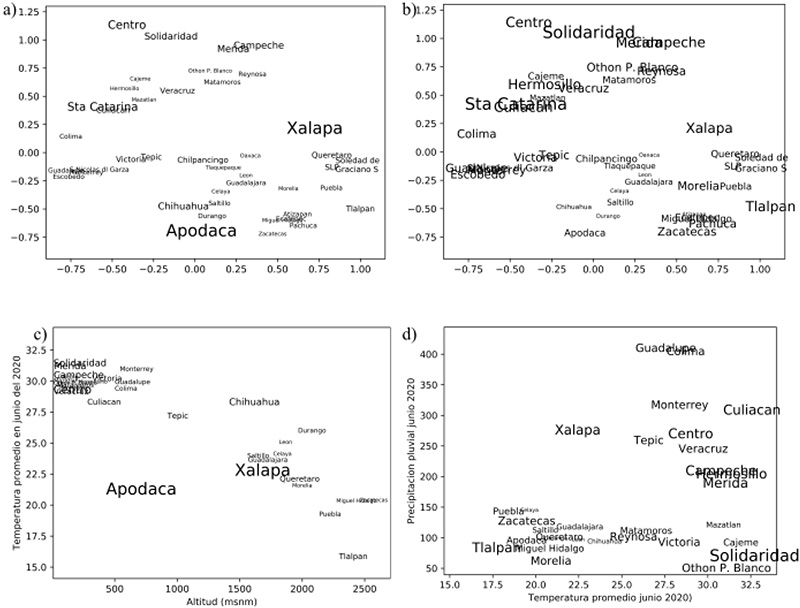
Figura 2. a) y b): Representación en dos dimensiones de las 42 ciudades de acuerdo con sus caracterizaciones en el espacio de siete atributos. La representación fue obtenida con escalamiento multidimensional, donde las ciudades que se encuentran próximas entre sí en la representación cuentan con descripciones semejantes en el espacio de atributos. Por ejemplo, Campeche y Mérida, mostradas como objetos muy semejantes entre sí, en realidad son descritas por atributos semejantes, como altas temperaturas en junio y septiembre, y no tan altas en enero, y con abundante precipitación en junio. Zacatecas y Pachuca son muy diferentes a las dos primeras, pero semejantes entre sí. El tamaño del nombre de la ciudad indica el nivel de anomalía de acuerdo con el algoritmo LOF. Se puede observar que Apodaca en Nuevo León, y Xalapa, en Veracruz, son mostrados como discrepancias. La razón de ello es que sus ciudades cercanas (en el espacio de atributos referido) son muy diferentes en cuanto a su vecindad a las dos ciudades. c) y d): Se muestra la proyección sobre dos de los siete atributos. Se observa que Apodaca tiene una temperatura más baja que las ciudades ubicadas en la misma altitud.
El concepto de distancia es fundamental en muchos aspectos del aprendizaje computacional. No obstante, caracterizar el grado de anomalidad de un objeto únicamente con el concepto de distancia puede llevar a caracterizaciones inestables. Para evitarlas, es necesario construir caracterizaciones más estables. Un concepto derivado del primero es la densidad. Ésta se define como el número de objetos que rodean a cada punto en el espacio de atributos. En la práctica, se define una vecindad en torno a cada punto, digamos, una esfera de radio r, y se lleva la cuenta, para cada punto, del número de objetos que se encuentran a una distancia r o menos.
A partir de la densidad, podemos darnos una idea de la distribución del número de vecinos de todos los objetos. El concepto anterior nos proporciona una buena aproximación a la diversidad de los datos, es mucho más poderoso, puede servir para comparar el nivel de semejanza entre vectores, y con ello, obtener un criterio de anomalía. A continuación, veamos cómo.


